In response to my last post, “The Long Tail of the Pareto Distribution,” Neil Gunther had the following comment:
“Unfortunately, you've fallen into the trap of using the ‘long tail’ misnomer. If you think about it, it can't possibly be the length of the tail that sets distributions like Pareto and Zipf apart; even the negative exponential and Gaussian have infinitely long tails.”
He goes on to say that the relevant concept is the “width” or the “weight” of the tails that is important, and that a more appropriate characterization of these “Long Tails” would be “heavy-tailed” or “power-law” distributions.
Neil’s comment raises an important point: while the term “long tail” appears a lot in both the on-line and hard-copy literature, it is often somewhat ambiguously defined. For example, in his book, The Long Tail, Chris Anderson offers the following description (page 10):
“In statistics, curves like that are called ‘long-tailed distributions’ because the tail of the curve is very long relative to the head.”
The difficulty with this description is that it is somewhat ambiguous since it says nothing about how to measure “tail length,” forcing us to adopt our own definitions. It is clear from Neil’s comments that the definition he adopts for “tail length” is the width of the distribution’s support set. Under this definition, the notion of a “long-tailed distribution” is of extremely limited utility: the situation is exactly as Neil describes it, with “long-tailed distributions” corresponding to any distribution with unbounded support, including both distributions like the Gaussian and gamma distribution where the mean is a reasonable characterization, and those like the Cauchy and Pareto distribution where the mean doesn’t even exist.
The situation is analogous to that of confidence intervals, which characterize the uncertainty inherited by any characterization computed from a collection of uncertain (i.e., random) data values. As a specific example consider the mean: the sample mean is the arithmetic average of N observed data samples, and it is generally intended as an estimate of the population mean, defined as the first moment of the data distribution. A q% confidence interval around the sample mean is an interval that contains the population mean with probability at least q%. These intervals can be computed in various ways for different data characterizations, but the key point here is that they are widely used in practice, with the most popular choices being the 90%, 95% and 99% confidence intervals, which necessarily become wider as this percentage q increases. (For a more detailed discussion of confidence intervals, refer to Chapter 9 of Exploring Data in Engineering, the Sciences, and Medicine.) We can, in principle, construct 100% confidence intervals, but this leads us directly back to Neil’s objection: the 100% confidence interval for the mean is entire support set of the distribution (e.g., for the Gaussian distribution, this 100% confidence interval is the whole real line, while for any gamma distribution, it is the set of all positive numbers). These observations suggest the following notion of “tail length” that addresses Neil’s concern while retaining the essential idea of interest in the business literature: we can compare the “q% tail length” of different distributions for some q less than 100.
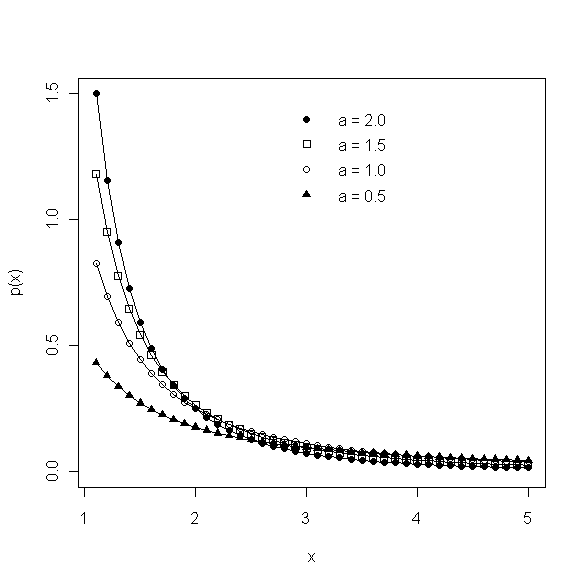
In particular, consider the case of J-shaped distributions, defined as those like the Pareto type I distribution whose distribution p(x) decays monotonically with increasing x, approaching zero as x goes to infinity. The plot below shows two specific examples to illustrate the idea: the solid line corresponds to the (shifted) exponential distribution:
p(x) = e–(x-1)
for all x greater than or equal to 1 and zero otherwise, while the dotted line represents the Pareto type I distribution with location parameter k = 1 and shape parameter a = 0.5 discussed in my last post. Initially, as x increases from 1, the exponential density is greater than the Pareto density, but for x larger than about 3.5, the opposite is true: the exponential distribution rapidly becomes much smaller, reflecting its much more rapid rate of tail decay.

For these distributions, define the q% tail length to be the distance from the minimum possible value of x (the “head” of the distribution; here, x = 1) to the point in the tail where the cumulative probability reaches q% (i.e., the value xq where x < xq with probability q%). In practical terms, the q% tail length tells us how far out we have to go in the tail to account for q% of the possible cases. In R, this value is easy to compute using the quantile function included in most families of available distribution functions. As a specific example, for the Pareto type I distribution, the function qparetoI in the VGAM package gives us the desired quantiles for the distribution with specified values of the parameters k (designated “scale” in the qparetoI call) and a (designated “shape” in the qparetoI call). Thus, for the case k = 1 and a = 0.5 (i.e., the dashed curve in the above plot), the “90% tail length” is given by:
> qparetoI(p=0.9,scale=1,shape=0.5)
[1] 100
>
For comparison, the corresponding shifted exponential distribution has the 90% tail length given by:
> 1 + qexp(p = 0.9)
[1] 3.302585
>
(Note that here, I added 1 to the exponential quantile to account for the shift in its domain from “all positive numbers” – the domain for the standard exponential distribution – to the shifted domain “all numbers greater than 1”.) Since these 90% tail lengths differ by a factor of 30, they provide a sound basis for declaring the Pareto type I distribution to be “longer tailed” than the exponential distribution.
These results also provide a useful basis for assessing the influence of the decay parameter a for the Pareto distribution. As I noted last time, two of the examples I considered did not have finite means (a = 0.5 and 1.0), and none of the four had finite variances (i.e., also a = 1.5 and 2.0), rendering moment characterizations like the mean and standard deviation fundamentally useless. Comparing the 90% tail lengths for these distributions, however, leads to the following results:
a = 0.5: 90% tail length = 100.000
a = 1.0: 90% tail length = 10.000
a = 1.5: 90% tail length = 4.642
a = 2.0: 90% tail length = 3.162
It is clear from these results that the shape parameter a has a dramatic effect on the 90% tail length (in fact, on the q% tail length for any q less than 100). Further, note that the 90% tail length for the Pareto type I distribution with a = 2.0 is actually a little bit shorter than that for the exponential distribution. If we move further out into the tail, however, this situation changes. As a specific example, suppose we compare the 98% tail lengths. For the exponential distribution, this yields the value 4.912, while for the four Pareto shape parameters we have the following results:
a = 0.5: 98% tail length = 2,500.000
a = 1.0: 98% tail length = 50.000
a = 1.5: 98% tail length = 13.572
a = 2.0: 98% tail length = 7.071
This value (i.e., the 98% tail length) seems a particularly appropriate choice to include here since in his book, The Long Tail, Chris Anderson notes that his original presentations on the topic were entitled “The 98% Rule,” reflecting the fact that he was explicitly considering how far out you had to go into the tail of a distribution of goods (e.g., the books for sale by Amazon) to account for 98% of the sales.
Since this discussion originally began with the question, “when are averages useless?” it is appropriate to note that, in contrast to the much better-known average, the “q% tail length” considered here is well-defined for any proper distribution. As the examples discussed here demonstrate, this characterization also provides a useful basis for quantifying the “Long Tail” behavior that is of increasing interest in business applications like Internet marketing. Thus, if we adopt this measure for any q value less than 100%, the answer to the title question of this post is, “No: The Long Tail is a useful concept.”
The downside of this minor change is that – as the results shown here illustrate – the results obtained using the q% tail length depend on the value of q we choose. In my next post, I will explore the computational issues associated with that choice.